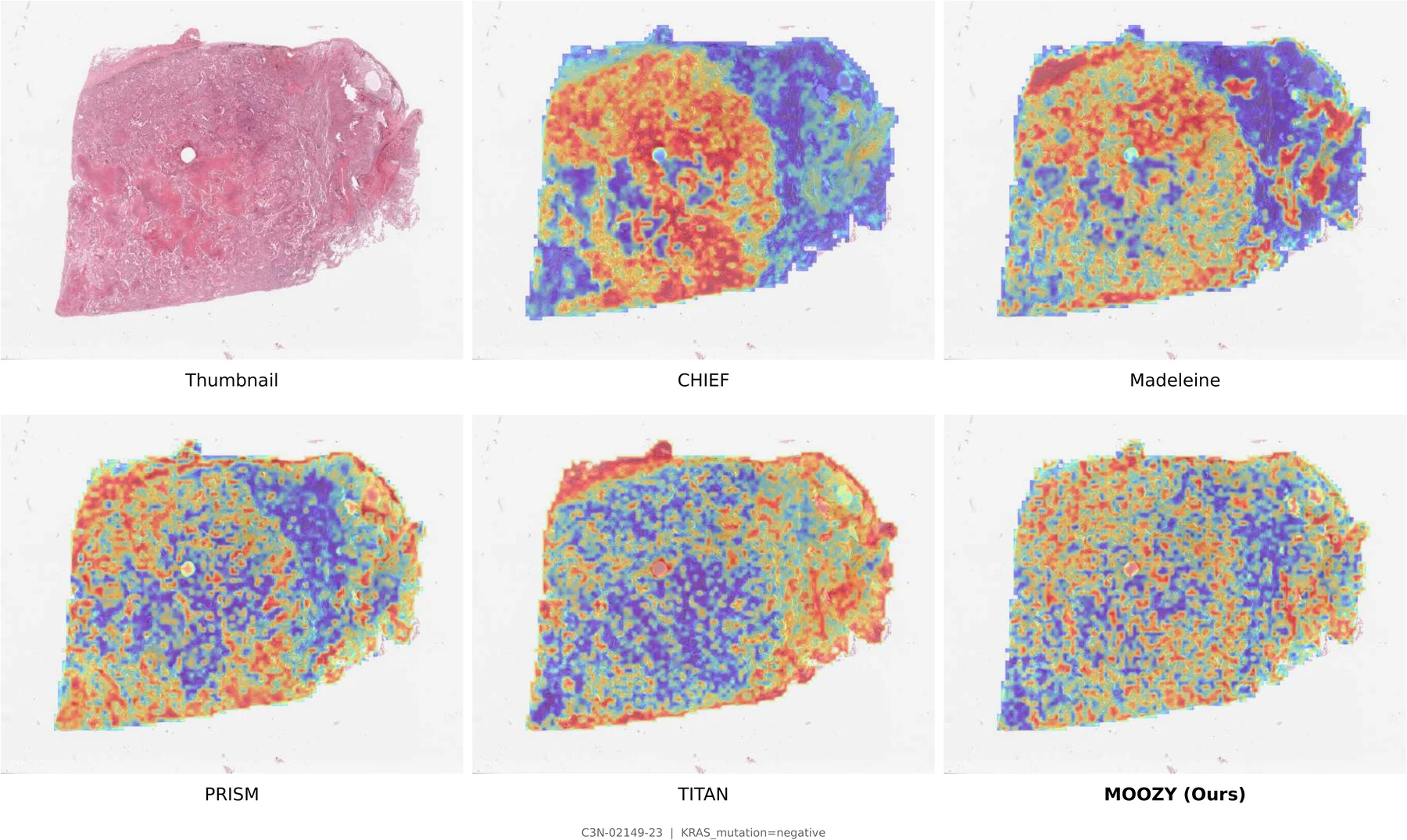
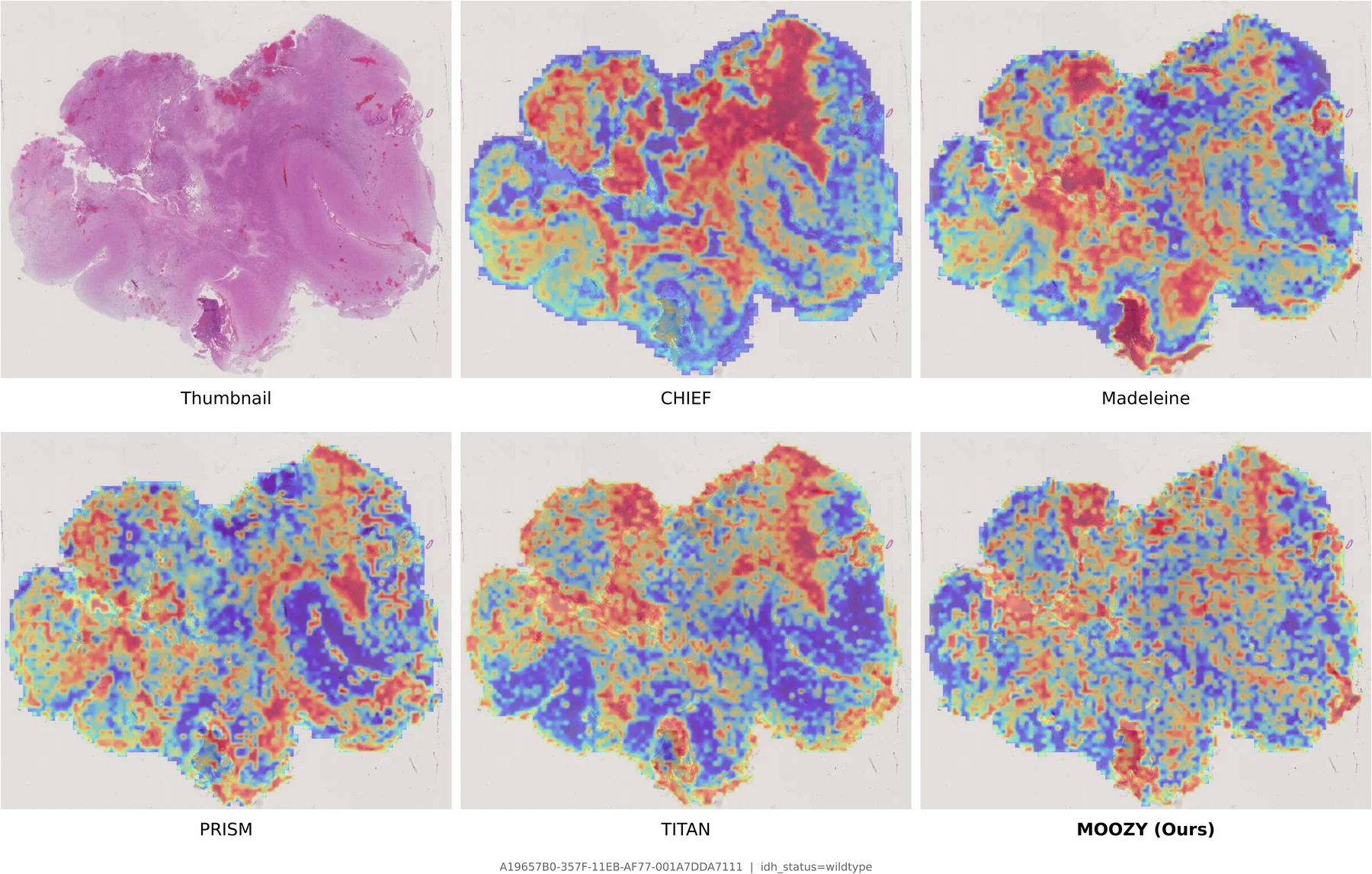
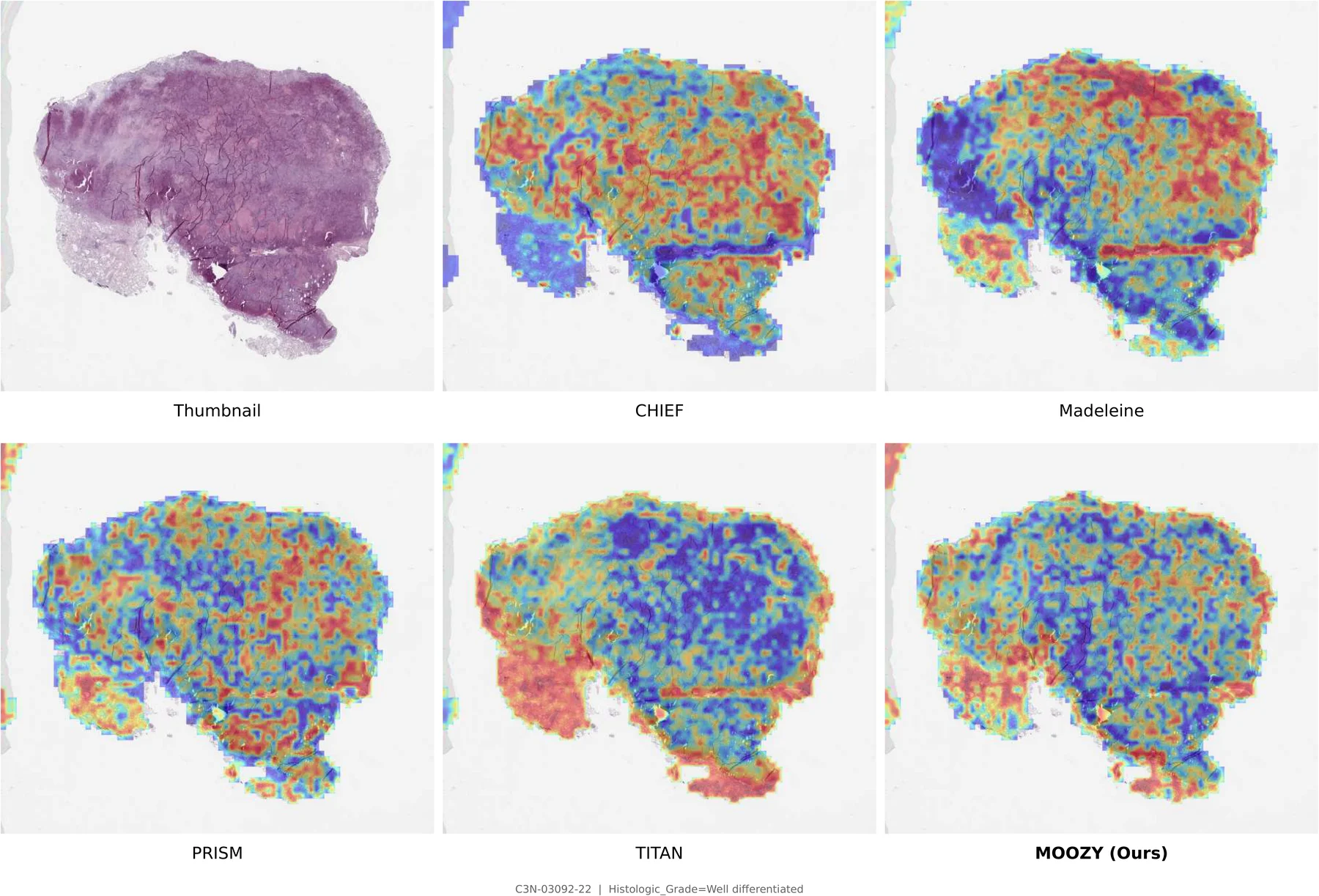
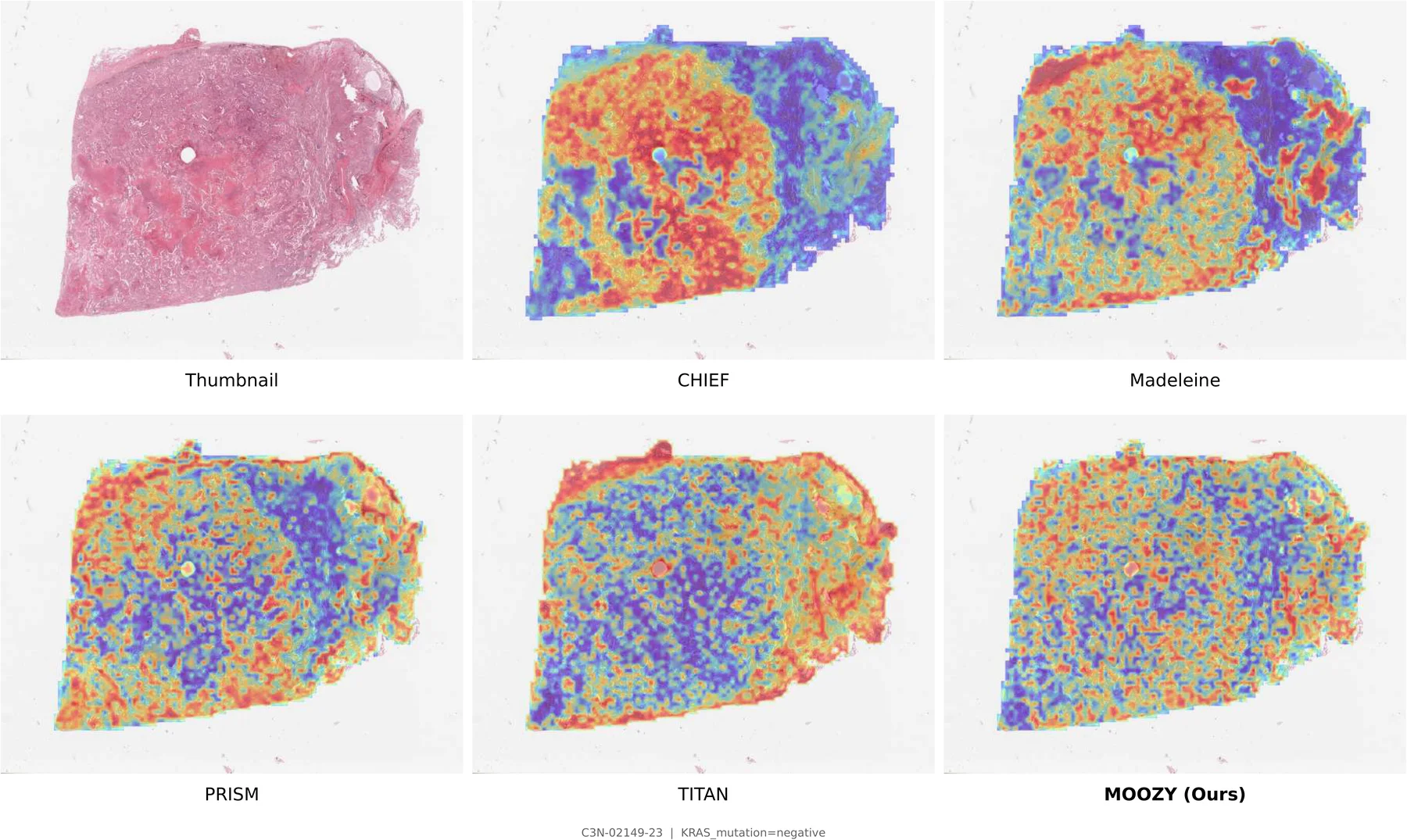
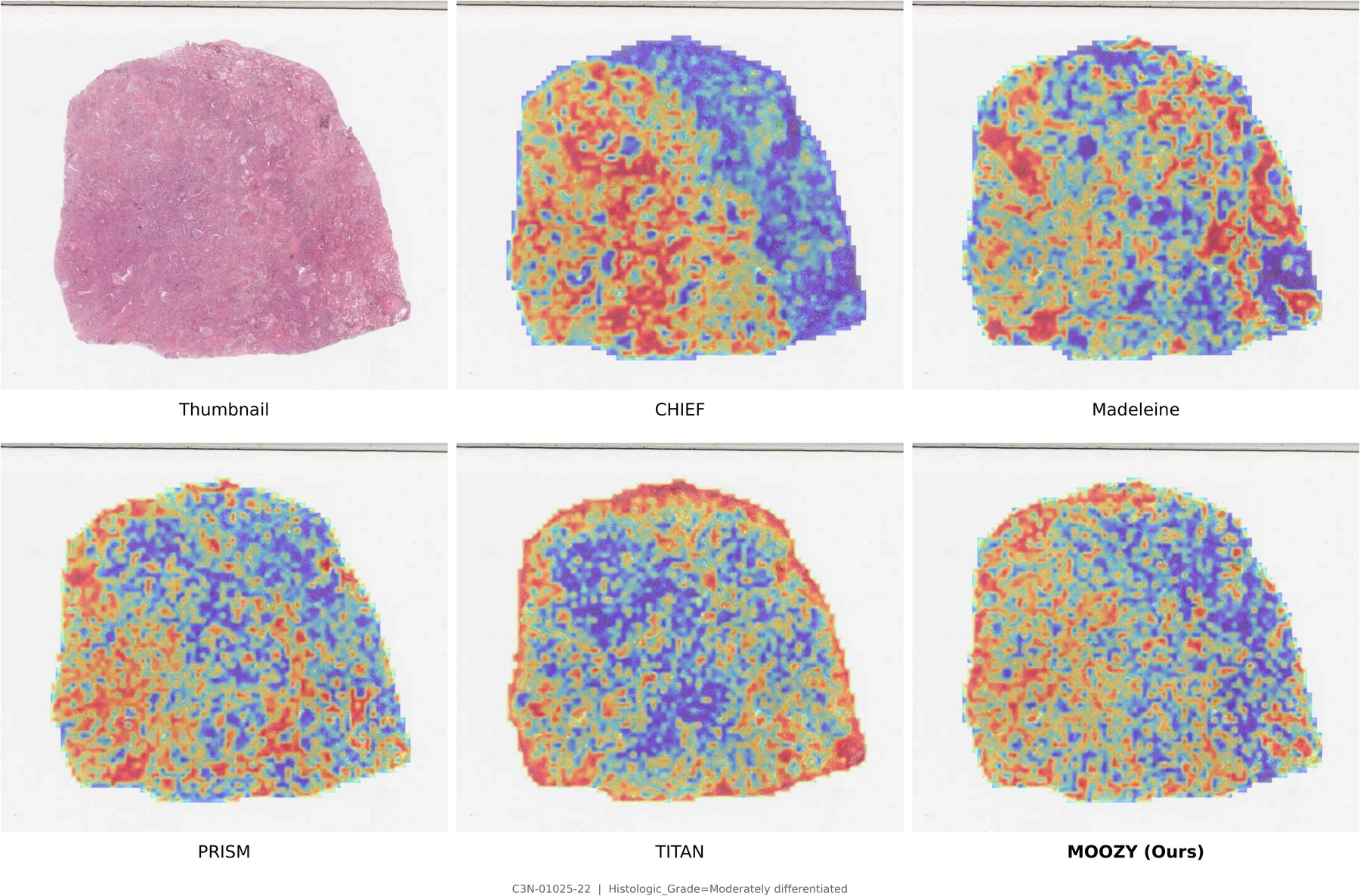
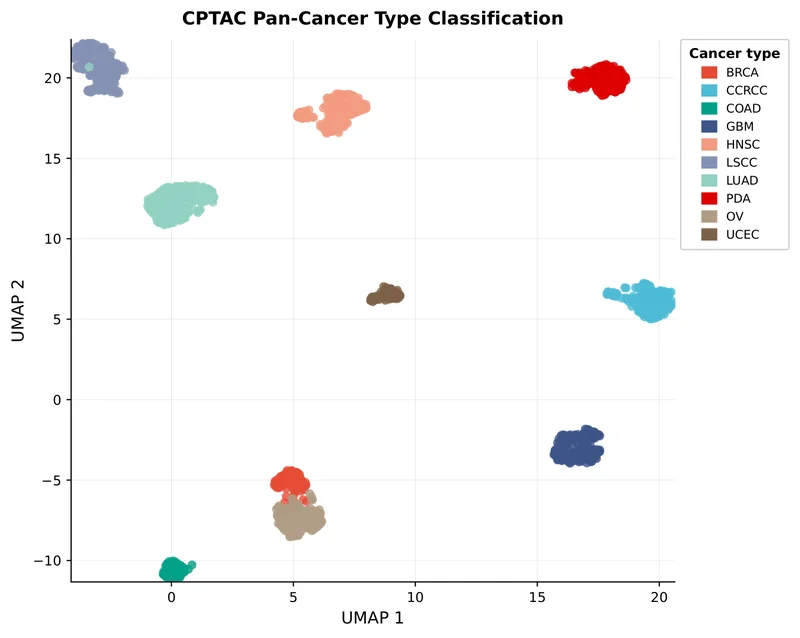
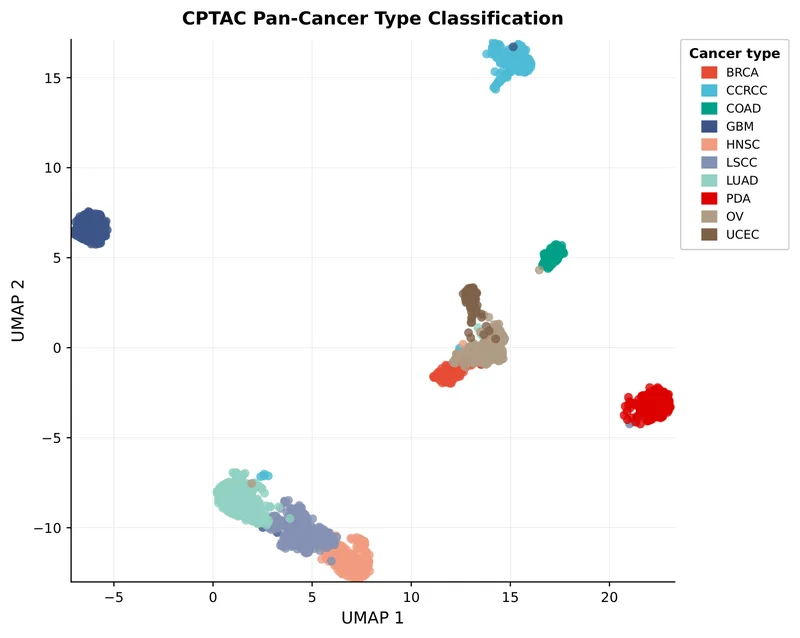
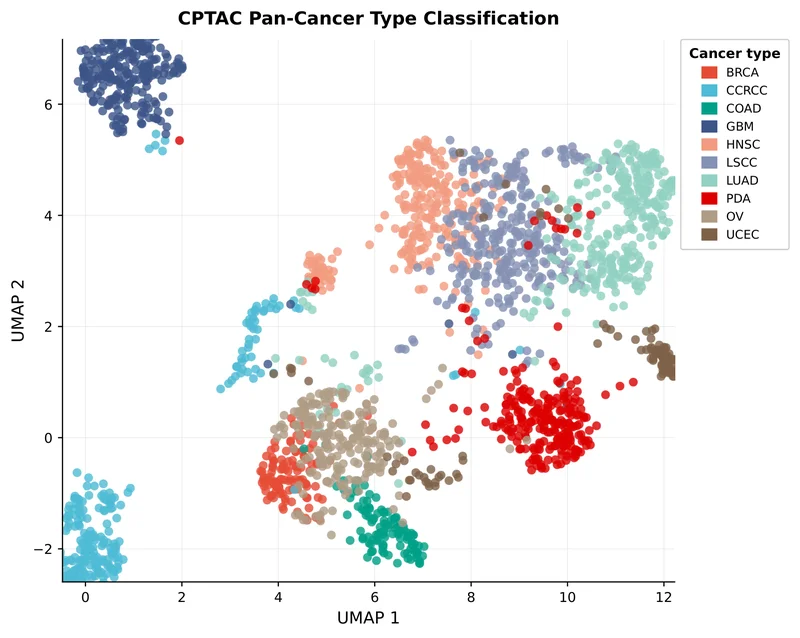
Two-Stage Training Pipeline
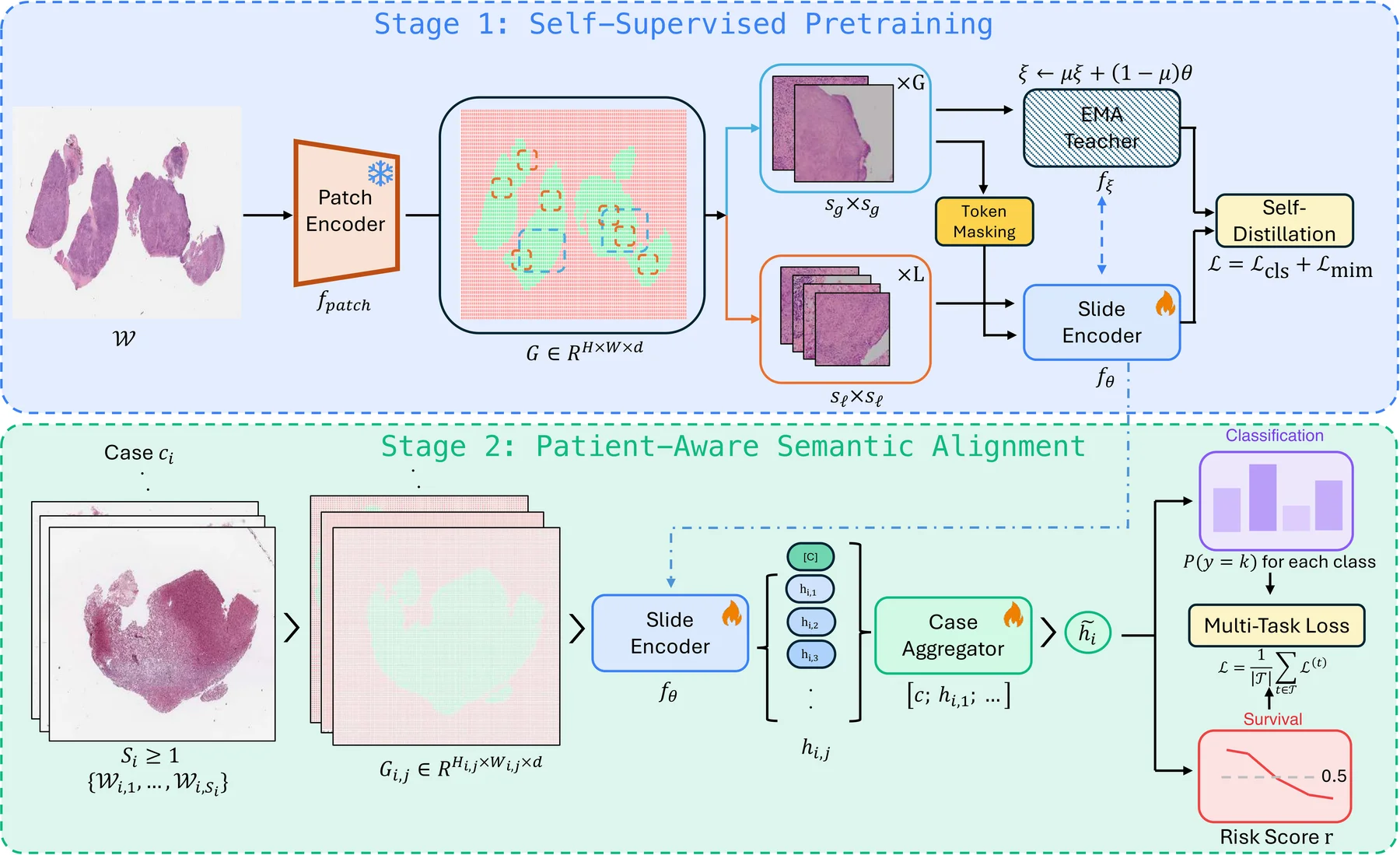
Stage 1 (top): A frozen patch encoder extracts per-patch features arranged into a spatial grid. Multi-scale crops are sampled with spatial augmentations and block-based masking. A student slide encoder and EMA teacher are jointly trained via CLS-level self-distillation and masked patch prediction. Stage 2 (bottom): The pretrained slide encoder produces per-slide embeddings; a case transformer aggregates them into a unified case embedding, routed to task-specific classification and survival heads.